



Tentu saja, ada banyak aspek dari replikasi MySQL, tapi fokus utama saya akan logistik - bagaimana peristiwa replikasi ditulis pada master, bagaimana mereka ditransfer ke budak replikasi dan kemudian bagaimana mereka diterapkan di sana. Perhatikan bahwa ini bukan replikasi pengaturan HOWTO, melainkan jenis Howstuffworks hal.
Peristiwa replikasi
Saya mengatakan peristiwa replikasi dalam artikel ini karena saya ingin menghindari diskusi tentang format replikasi yang berbeda. Ini tercakup cukup baik di manual MySQL sini. Sederhananya, peristiwa dapat menjadi salah satu dari dua jenis:
Statement based - dalam hal ini adalah pertanyaan write
Row based - dalam hal ini ini adalah perubahan catatan, semacam baris diffs jika Anda akan
Tapi selain itu, saya tidak akan kembali ke perbedaan replikasi dengan format replikasi yang berbeda, terutama karena ada sangat sedikit yang berbeda ketika datang ke mengangkut perubahan data.
Pada master
Jadi sekarang mari saya mulai dengan apa yang terjadi di master. Untuk replikasi untuk bekerja, pertama-tama guru harus menulis peristiwa replikasi untuk log khusus yang disebut log biner. Hal ini biasanya kegiatan yang sangat ringan (dengan asumsi peristiwa tidak disinkronkan ke disk), karena menulis buffer dan karena mereka berurutan. Biner file log menyimpan data yang budak replikasi akan membaca nanti.
Setiap kali seorang budak replikasi terhubung ke master, guru menciptakan thread baru untuk sambungan (mirip dengan salah satu yang digunakan untuk setiap client server lainnya) dan kemudian melakukan apa klien - replikasi budak dalam hal ini - meminta. Sebagian besar yang akan menjadi (a) budak replikasi makan dengan kejadian dari log biner dan (b) memberitahukan budak tentang peristiwa yang baru ditulis ke log biner.
Budak yang up to date sebagian besar akan membaca peristiwa yang masih cache di OS cache pada master, sehingga ada tidak akan ada disk fisik membaca pada master untuk memberi makan peristiwa log biner ke slave (s). Namun, ketika Anda menghubungkan budak replikasi yang beberapa jam atau bahkan berhari-hari di balik, itu akan awalnya mulai membaca log biner yang jam atau hari ditulis lalu - Master mungkin tidak lagi memiliki ini cache, sehingga disk membaca akan terjadi. Jika guru tidak memiliki sumber informasi gratis IO, Anda mungkin merasa benjolan pada saat itu.
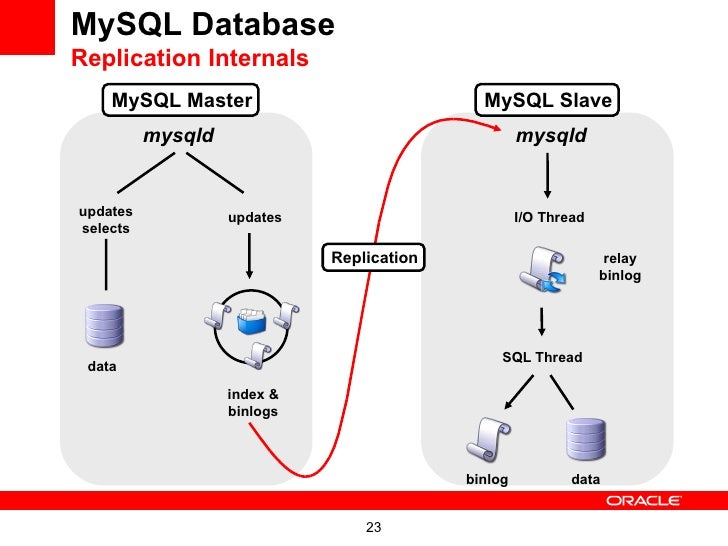
Pada replika
Sekarang mari kita lihat apa yang terjadi pada budak. Ketika Anda mulai replikasi, dua benang dimulai pada budak:
1. IO Thread
Proses ini disebut benang IO terhubung ke master, membaca peristiwa log biner dari master karena mereka datang dan hanya salinan mereka ke sebuah file log lokal yang disebut log relay. Itu saja.
Meskipun hanya ada satu thread membaca log biner dari master dan log estafet satu tulisan di budak, sangat jarang menyalin peristiwa replikasi adalah elemen lambat dari replikasi. Mungkin ada delay jaringan, menyebabkan penundaan stabil beberapa ratus milidetik, tapi itu tentang hal itu.
Jika Anda ingin melihat di mana benang IO saat ini, periksa berikut dalam "acara budak Status \ G":
Master_Log_File - file yang terakhir disalin dari master (sebagian besar waktu itu akan menjadi sama dengan log biner terakhir yang ditulis oleh master)
Read_Master_Log_Pos - log biner dari master disalin ke log relay pada budak sampai posisi ini.
Dan kemudian Anda dapat membandingkannya dengan output dari "show Status tuan \ G" dari master.
2. SQL Thread
Kedua proses - benang SQL - membaca peristiwa dari log estafet disimpan secara lokal pada budak replikasi (file yang ditulis oleh IO benang) dan kemudian berlaku mereka secepat mungkin.
Thread ini adalah apa yang orang sering menyalahkan karena single-threaded. Akan kembali ke "pertunjukan budak Status \ G", Anda bisa mendapatkan status SQL benang dari variabel-variabel berikut:
Relay_Master_Log_File - log biner dari master, bahwa benang SQL adalah "bekerja pada" (pada kenyataannya itu bekerja pada log relay, jadi itu hanya cara yang nyaman untuk menampilkan informasi)
Exec_Master_Log_Pos - yang posisi dari master log biner sedang dieksekusi oleh SQL benang.
Replikasi lag
Sekarang saya ingin menyentuh secara singkat subyek replikasi lag dalam konteks ini. Ketika Anda berurusan dengan replikasi lag, hal pertama yang Anda ingin tahu adalah yang mana dari dua benang replikasi belakang. Sebagian besar waktu itu akan menjadi benang SQL, masih masuk akal untuk periksa. Anda dapat melakukannya dengan membandingkan variabel Status replikasi disebutkan di atas untuk master Status log biner dari output dari "show Status tuan \ G" dari master.
Jika hal itu terjadi untuk menjadi benang IO, yang, seperti yang saya sebutkan berkali-kali sudah, sangat jarang, satu hal yang mungkin ingin mencoba untuk mendapatkan yang tetap adalah memungkinkan budak dikompresi protokol.
Jika tidak, jika Anda yakin itu adalah SQL benang, maka Anda ingin memahami apa alasannya dan bahwa Anda biasanya dapat mengamati dengan vmstat. Memonitor aktivitas server dari waktu ke waktu dan melihat apakah itu adalah "r" atau "b" kolom yang "scoring" sebagian besar waktu. Jika itu adalah "r", replikasi adalah CPU-terikat, sebaliknya - IO. Jika tidak konklusif, mpstat akan memberikan visibilitas yang lebih baik dengan benang CPU.
Catatan ini mengasumsikan bahwa tidak ada aktivitas lain terjadi pada server. Jika ada beberapa aktivitas, maka Anda juga mungkin ingin melihat diskstats atau bahkan melakukan review permintaan untuk SQL thread untuk mendapatkan gambar yang bagus.
Jika Anda menemukan bahwa replikasi CPU terikat, ini mungkin sangat membantu.
Jika IO terikat, maka memperbaikinya mungkin tidak mudah (atau lebih tepatnya, sebagai murah). Mari saya jelaskan. Jika replikasi IO terikat, sebagian besar waktu itu berarti bahwa SQL benang tidak dapat membaca cukup cepat karena membaca adalah threaded tunggal. Ya, Anda punya hak itu - itu membaca yang membatasi kinerja replikasi, tidak menulis. Mari saya jelaskan lebih lanjut.
Asumsikan Anda memiliki RAID10 dengan sekelompok disk dan write-back cache. Menulis, meskipun mereka serial, akan cepat karena mereka buffered dalam cache controller dan karena internal kartu RAID dapat memparalelkan menulis ke disk. Oleh karena itu replikasi budak dengan hardware yang sama dapat menulis secepat Master bisa.
Sekarang Membaca. Ketika workset Anda tidak cocok di memori, maka data yang akan mendapatkan dimodifikasi akan harus dibaca dari disk pertama dan ini adalah di mana ia dibatasi oleh sifat single-threaded replikasi, karena satu thread hanya akan pernah membaca dari satu disk pada suatu waktu.
Yang sedang berkata, salah satu solusi untuk memperbaiki replikasi IO-terikat adalah untuk meningkatkan jumlah memori sehingga bekerja mengatur cocok di memori. Lain - mendapatkan IO perangkat yang dapat melakukan jauh lebih operasi IO per detik bahkan dengan satu benang - disk tercepat tradisional dapat melakukan hingga 250 IOPS, SSD - di urutan 10.000 IOPS.

Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation.
0 komentar:
Posting Komentar